区分性训练用在命令词的论文
==Chen, Zhehuai, Yanmin Qian, and Kai Yu. “Sequence discriminative training for deep learning based acoustic keyword spotting.” Speech Communication 102 (2018): 100-111.==
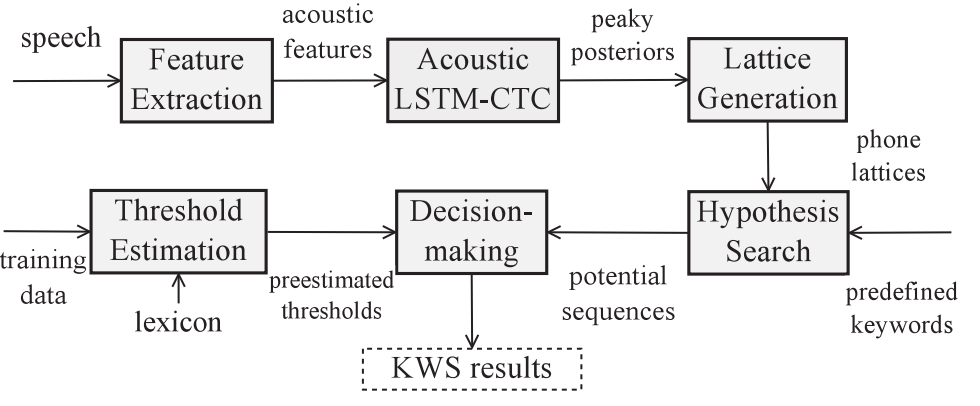
post-processing 后处理:
acoustic KWS usually does not require a language model but needs post-processing after the frame-level acoustic model inference
HMM
- The post-processing method can be categorized into three groups:
Posterior smoothing
aim to filter out the noise posterior output by heuristic methods 启发式方法滤除噪声后验输出
(Chen, G., Parada, C., Heigold, G., 2014a. Small-footprint keyword spotting using deep neural networks. Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, pp. 4087–4091.)
Model based inference
aim to filter out the noise posterior output by data-driven methods 数据驱动方法滤除噪声后验输出
(Ge, F., Yan, Y., 2017. Deep neural network based wake-up-word speech recognition with two-stage detection. Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 2761–2765. New Orleans, USA)
filler based decoding(In some recent works (Chen et al., 2014b; 2017a), a small language model can be applied in the filler modeling and shows moderate improvement )
model out-of-domain search space
(Chen, I.-F., Ni, C., Lim, B.P., Chen, N.F., Lee, C.-H., 2014b. A novel keyword+ lvcsr-filler based grammar network representation for spoken keyword search. Proceedings of the 2014 9th International Symposium on Chinese Spoken Lansguage Processing (ISCSLP). IEEE, pp. 192–196.)
(Chen, Z., Qian, Y., Yu, K., 2017a. A unified confidence measure framework using auxiliary normalization graph )
the possible competing words are usually not enumerable and the competing hypotheses generation is computationally expensive if using the same procedure as in LVCSR :
Chen, S.F., Kingsbury, B., Mangu, L., Povey, D., Saon, G., Soltau, H., Zweig, G., 2006. Advances in speech transcription at ibm under the darpa ears program. IEEE Trans. Audio Speech. Lang. Process. 14 (5), 1596–1608
CTC
- MED 最小编辑距离
CTC中的MED方法难以引入HMM的原因
- MED在lattice上进行,CTC有尖峰,可降低复杂度,HMM无尖峰
- HMM的神经网络输出$p(o_{ut}|q_t)$,区分性训练过程已经有了该信息
区分性训练的non-keyword部分:
MMI准则公式为:$\large{\mathcal{F}_{MMI}=\sum_ulog\frac{P(\textbf{O}_u|\textbf{W}_u)^kP(\textbf{W}u)}{\sum{\textbf{W}}P(\textbf{O}u|\textbf{W})^kP(\textbf{W})}=\sum_ulog\frac{\sum{L\in{\mathcal{L}(W)}}p(\textbf{O}|\textbf{L})^kP(\textbf{L}|\textbf{W})^kP(\textbf{W}_u)}{\sum_Wp(\textbf{O}_u|\textbf{W})^kP(\textbf{W})}}$
由于不知道non-keyword序列,通过补偿composite alternate hypotheses 的概率来模拟这个过程,
提出两个建模单元:
- filler model for non-keyword speech 建模非keyword
- anti-keyword model for mis-recognitions 建模易与keyword混淆的音
实际上该方法不可行
(Sukkar, R.A., Lee, C.-H., 1996. Vocabulary independent discriminative utterance verification for nonkeyword rejection in subword based speech recognition. IEEE Trans. Speech Audio Process. 4 (6), 420–429.)
(Sukkar, R.A., Setlur, A.R., Rahim, M.G., Lee, C.-H., 1996. Utterance verification of keyword strings using word-based minimum verification error (wb-mve) training. Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. 1. IEEE, pp. 518–521. )
在单词级CTC(Fernández et al.,2007)中,虽然它自然是一个序列级标准,但它不直接模拟非关键字元素。也就是说,在关键字之间插入空格以模拟它们之间的上下文。因此,序列级准则提高了关键字之间而不是关键字与非关键字之间的序列预测能力
我们现在的训练数据,都是单独的关键词句子、非关键词句子,在关键词训练数据中有非关键词,可以提高预测能力?会不会增加far?
A per-frame non-uniform weight can be added into the loss functions; operates inMCE. The key point is to emphasize the loss during the span of possible keyword false rejection and false alarm in the training data.
(Meng, Z., Juang, B.-H., 2016. Non-uniform boosted mce training of deep neural networks for keyword spotting. Proceedings of the Interspeech 2016. pp. 770–774. )
- LF-MMI与原始MMI的区别::
- 分子:原始分子文本对齐序列用的硬对齐的alignment,chain model用软对齐,左右帧移窗口,全部算进分子。
- 分母:chain model语言模型用的3gram phone,sub-word level语言模型(chain model即使用音节建模,音节相当于“phone”,也是子词了,训练的3gram phone也是3gram syllable)
- 改变topo结构,chain model用的标签状态pdf后接可选的(属于该状态的)blank状态 pdf,(还是用的三音素)
- 输出帧下采样3倍
- 本论文与LF-MMI的区别:
- 用单音素建模(改善很小?但是可以节约计算量)
- 这里blank可以在标签前,也可以前后都有。这叫做”label delay“,能改善性能(不确定就可以先输出blank的意思?)(eer从3.1下降到3.0,改善很小?)
- LF-MMI公式改进为LF-bMMI
- 训练时加重出现false alarm和false rejection的训练数据的loss
实验结果
- LSTM与TDNN比较:对于hmm的lf-mmi来说,blstm效果和tdnn一致,参数量还更大,所以用tdnn就可以了
- 对KWS任务,依赖的上下文并不长
- 小模型参数下会更限制lstm效果
- tdnn速度更快
- CI与CD建模单元比较:效果一致,CI的数量更小,用CI就可以了
- 不同交叉熵正则权重,该训练集中权重0.7合适,会有一定影响,这是因为测试时语言模型和训练不同,因此要权衡
- topo结构比较,BP最佳(BPB由于训练数据更少,提升很小(文章用了“显著性检验”指标来衡量提升幅度))
实验结果来看,最有效的还是训练时引入不同权重策略(给false alarm和false rejection样本更高的训练权重)
训练时引入不同权重策略如何实现
雷博想法:先训练一个不错的模型,然后解码,根据解码结构,确定哪些是false alarm和false rejection,在egs的post中(本来都是1),提高他们的概率,再训练。
==Wang Y, Lv H, Povey D, et al. Wake Word Detection with Alignment-Free Lattice-Free MMI[J]. arXiv preprint arXiv:2005.08347, 2020.==
==Wang, Yiming. WAKE WORD DETECTION AND ITS APPLICATIONS. Diss. Johns Hopkins University, 2021.==王一鸣博士论文
==github开源代码==:The code and recipes are available in Kaldi [24]: https://github.com/kaldi-asr/kaldi/tree/master/egs/{snips,mobvoi,mobvoihotwords}.
==github代码==:https://github.com/YiwenShaoStephen/pychain
==csdn 博客==:Wake Word Detection with Alignment-Free Lattice-Free MMI
思想
- 提出alignment free LF-MMI,不需要对齐分子lattice
- 不把唤醒词里面每个音素建模,而是把整个唤醒词建模 model the whole wake phrase ,用一个固定状态数的HMM去建模唤醒词(该数量少于唤醒词音素组成数量)
- keyword、non-keyword、sil 都各用一个HMM建模
- 针对唤醒任务,提出alignment free LFMMI,分子不用对齐文本得到分子lattice,由于文本就是keyword/non-keyword,文本只有一个HMM,直接遍历HMM所有可能路径,求路径和概率。(直接用文本图上添加自环,让解码更自由,前后向可选的路径更多)
- 负样本文本一般比较长,一个HMM可能建模不了,因此把负样本切成和正常本长度差不多,每个负样本的训练文本为freetext(一个HMM),就可以去生成egs了
- 负样本如果不segment,会严重过拟合
- 该方法能有效改善FAR高
- 分母图上路径权重:按正负样本比例来分配
分子图fst:用一个文本构成(一个文本就是一个单词,一个单词用一个HMM建模)

分母图fst:可以理解成word 并联序列,只不过添加了sil(不是loop,不能重复走)
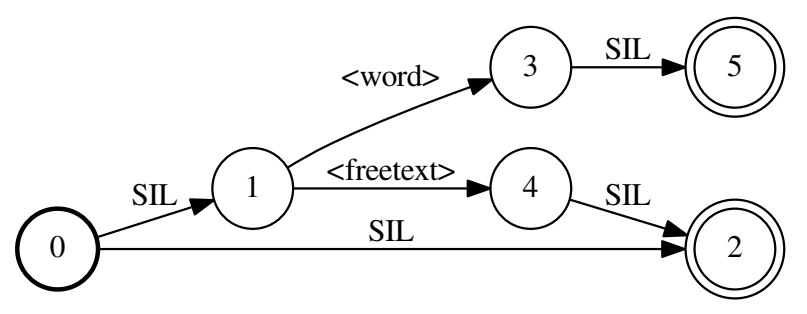
实验
- 负样本进行了分块chunk,==chunk长度和正样本差不多==,
- 负样本后继chunk重叠0.3s,使得前一个chunk被截掉的单词有机会在后继chunk全词出现
- 声学模型:TDNN-F,分解到两个低秩矩阵,前一个矩阵是半正定的,确保高维到低维信息不会丢失
- 前一层的输入乘上缩放比例0.66与本层输入加和(是add,而不是concatenate)
- 拼帧结构:把本来要拼在一层的结构 分解到两层会更好,比如第一层拼(-3,0,3),第二层拼(0),更好的做法是第一层拼(-3,0),第二层拼(0,3)
- 训练了一个alignment-free LF-MMI后,对齐lattice,重新训练一个普通的LF-MMI,效果会更好
- alignment-free体现在:
- (雷博)不需要GMM-HMM训练过程,不需要对齐ali文件
- 不需要对齐训练样本然后统计得到phone-lm
- 一个没有一点对齐能力的模型(0.mdl)也可以拿来使用的
- nnet3-chain-e2e-get-egs分子cegs生成,直接用text构建的fst,找到所有可能的fst中的状态序列求和就是分子,普通的还要由fst构建lattice?(感觉二者差不多)
- 博士论文中比较了不同topo结构:
- 把sil和freetext表示在一个HMM中,该HMM有多种可走的路径,这样就能够表示当训练样本前后是非命令词,中间是静音的情况。结果是增加了训练难度,误拒率很高,只有对齐准确的初始模型可能会得到好一点的误拒率,但是还是不好,因此最好不要把sil和freetext放在一起建模
- 用5状态建模HMM,效果比3状态好
注意
- 雷博说:
- 负样本切chunk后,要注意正负样本比例,不要让负样本远远多于正样本。
- 切割负样本(长文本切到短文本)时,文本不知道对应的是sil还是freetext,不好得知文本,把静音段也视作freeetext会有问题
- 实验效果好,可能由于数据集较小
在线解码
- 解码FST:其实长得有点像分母图,不同之处在于是起始状态和终止状态在同一个结点,使得可以生成词串,比如生成word后还可以生成freetext,再生成word等等,文本串;而分母图要不然就走freetext,要不然就走word,不能都串行出现。
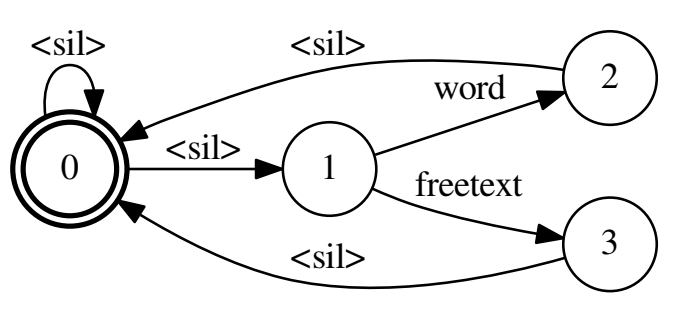
在线解码:一个chunk一个chunk解码,每次解码了一个chunk后,就去更新immortal token和prev_immortal token(在所有active tok里找公共祖先(emitting[0],或者说tokenOne),作为immortal tok,把前一次的immortal tok作为prevImmortal tok),每次在两个immortal tokens之间的路径寻找(backtrace)是否有唤醒词,实现了逐chunk搜索。
每处理过一段固定长度的录音后,我们用更新不朽token算法来回溯最近两个“不朽token”中间的这些帧,检查这部分回溯是否包含唤醒词。如果发现唤醒词则停止解码,如果没有唤醒词继续解码。(不朽token是现存激活token的共同祖先)
这个是基于这样一个假设:如果现有的存活的部分假设都是来自于前一个时刻的相同的token(不朽token),同时在这之前的所有的假设都已经压缩到了这一个token上,我们就可以从这个“不朽token”检查是否具有唤醒词 [csdn]
伪代码 online decoding:

- 更新immortal token,用于回溯

代码实现
The code and recipes are available in Kaldi [24]: https://github.com/kaldi-asr/kaldi/tree/master/egs/{snips,mobvoi,mobvoihotwords}.
本文中引入了一种不需要对齐(Alignment-free)、不需要词图的(Lattice-Free MMI)鉴别性准则训练的模型
相比Lattice-free MMI准则需要额外修改一下发音字典、HMM拓扑结构
1.HMM拓扑结构(KW和freetext)用的是5个状态;silence用的是2个状态,但是保持(Lattice-free MMI)的结构self-loop-pdf和forward-pdf对应两个不同的PDF-id,因此神经网络共82+21=18个pdf
2.分子图与分母图
分子图和chain的不同点在于:不需要依赖对齐结果生成label对应的图,生成一个非扩展的fst,在训练过程中通过前后向算法更加灵活的学习对齐结果
分母图和chain的不同点在于:phone级别的语言模型不再需要通过训练数据训练得到,直接手动生成一个语言模型fst,一共3条路径,关键词路径、freetext、silence,其中关键词和freetext前后都可加silence。每一条路径上的权重受训练数据中正负样本的占比因素影响
3.声学模型
使用TDNN-F模型(因式分解的TDNN),将一层的参数矩阵分解成两个低秩矩阵、第一个矩阵强制限制为半正定矩阵
模型(20层每层80节点)存在跨层连接,前一层的输入乘上缩放比例0.66与本层输入加和。
4.数据预处理和增强
对于负样本(存在很多样本时长较长)会按照正样本的时长分布,对负样本进行切段,每一段分配一个负样本标签。
增强:尽管训练数据很多是在实际场景中录制的,增强后效果仍然后提升
5.解码
手动构造词级别的解码网络FST,每条路径上的权重生成和分母图的LM-fst图方式是一样的。在开始token和结束token上增加从结束token到开始token的空边,原因是音频中可能存在唤醒词和其他可能的音频交叉现象。
在线解码的过程中:每处理过一段固定长度的录音后,我们用更新不朽token算法来回溯最近两个“不朽token”中间的这些帧,检查这部分回溯是否包含唤醒词。如果发现唤醒词则停止解码,如果没有唤醒词继续解码。(不朽token是现存激活token的共同祖先)
这个是基于这样一个假设:如果现有的存活的部分假设都是来自于前一个时刻的相同的token(不朽token),同时在这之前的所有的假设都已经压缩到了这一个token上,我们就可以从这个“不朽token”检查是否具有唤醒词
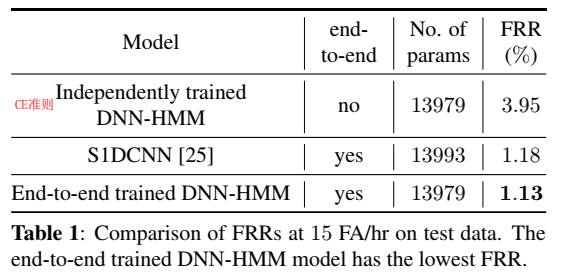
- 与其他模型的对比结果
==Shrivastava A , Kundu A , Dhir C , et al. Optimize What Matters: Training DNN-Hmm Keyword Spotting Model Using End Metric[C]// ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021.== Apple
思路
- 提出状态分类精度和命令词识别的目标不一致,分类精度高不代表检测分数高
- 从目标检测领域迁移而来提出IOU loss function:关键词groundtruth起止时间与预测的起止时间交集/并集,但是这篇论文不是真的用这个IOU loss,而是借鉴了IOU loss,原始IOU的groundtruth的起止时间区域,到了这边就是groundtruth keyword;而预测的起止时间,变成是viterbi对齐keyword后的区域,没有groundtruth的起止时间,而是一心要最大化positive sample预测的起止时间内的平均概率(和最小化negative sample预测的起止时间内的平均概率)
- 特地挑选子词+垃圾词作为负样本,从训练样本入手减少误唤醒
- 增加数据已经不能提升模型效果,可能是由于唤醒任务太简单,因此把目标函数弄复杂一点,增加训练难度,如果还能训练好的话,原本的唤醒任务也会训练得很好
- 把ground-truth(关键词)分成两部分并交换次序比如“静音”,变成“音静”,构建新的负样本,这样打乱顺序,可以强迫模型学会前后顺序(一定要减小音量才能唤醒,音量减小不能唤醒)
训练
- 训练时,根据viterbi对齐(训练时文本已知)(不是前后向,前后向是路径求和,这里是找最佳路径)找到最佳路径,得到路径分数,找到关键词的起始位置,得到关键词平均路径分数,记为检测分数$d$,$d=v_C(T)$,其中,C是关键词末尾状态
- 使用 hinge loss,loss function:
- 使用 hinge loss,loss function:$\large{L_{e2e}=\min_\limits{\theta}\sum_\limits{j\in{X_p}}max(0,1-d_j)+\sum_\limits{j\in{X_n}}max(0,1+d_j)}$,其中,p是正样本,n是负样本
- 一个唤醒词,正负样本比例1:30,50w样本
结果
==X. Wang, S. Sun, C. Shan, J. Hou, L. Xie, S. Li, and X. Lei, “Adversarial examples for improving end-to-end attention-based small-footprint keyword spotting,”in Proc. ICASSP, 2019, pp. 6366–6370.==
思路
kws里的false alarmed和false rejected样本作为对抗样本adversarial examples,用fast gradient sign method(FGSM)构建对抗样本,作为数据增广;
用模型输出正确的样本(输出为ground-truth),对样本输入进行扰动,使得模型输出不正确,这种新的输入,来作为对抗样本:
a pair of correctly-classified example $(x_i;y_i) $ ,其中$y_i$是ground-truth,对抗样本$x_i^{adj}=x_i+\delta_i$,并且满足$y_i\neq{f(x_i^{adv};\theta)}$,其中,${\Vert \delta_i \Vert}\ll{\Vert x_i \Vert}$
FGSM试图在输入空间中找到一个方向,使loss函数有效地增大,这个方向通过对输入求导来获得
$\delta_i^{FGSM}=\epsilon{sign}(\frac{L(y_i,\partial f(x_i;\theta))}{\partial x_i})$ (sign是符号函数 -1,1)
$x_i^{adv}=x_i+\delta_i^{FGSM}$
其中,$\epsilon$是调节扰动幅度的一个小常数
添加一点点扰动,模型预测错误说明:神经网络模型的输出相对于输入是不平滑的,在输入空间存在“盲点”。该模型很不smooth;
对抗样本生成:先训练一个好的模型后,对样本中的正样本添加扰动(只对keyword segment区域);对样本中的负样本添加扰动(全部区域),然后再retrain
用对抗样本能最大提高模型性能,模型最少见对抗样本的这种情况,而用随机扰动,模型只能改善一点;
模型
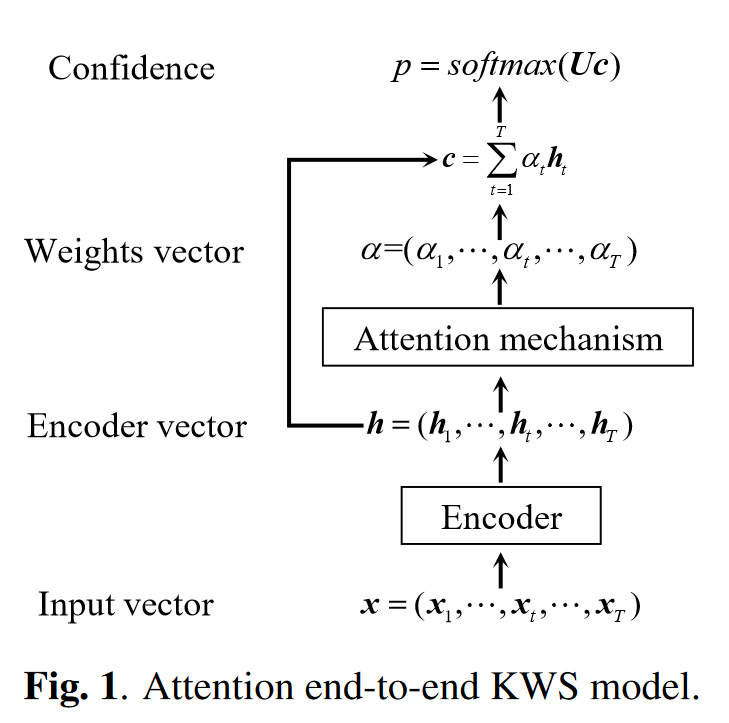
总体是一个attention结构,encoder是一个1层GRU,
训练
- 正样本差不多2s,因此把负样本也segment成最大2s;
- 在一个训练好的模型基础上,再retrain;retrain的过程为:在每个minibatch中,动态生成对抗样本;
- 只对正样本做对抗样本生成,效果最好;
测试
- 200帧窗长,1帧帧移
==Goodfellow, Ian J., Jonathon Shlens, and Christian Szegedy. “Explaining and harnessing adversarial examples.” arXiv preprint arXiv:1412.6572 (2014).==ciations:10772
思路
提出the fast gradient sign method (FGSM)
常规的分类模型训练在更新参数时都是将参数减去计算得到的梯度,这样就能使得损失值越来越小,从而模型预测对的概率越来越大。既然无目标攻击是希望模型将输入图像错分类成正确类别以外的其他任何一个类别都算攻击成功,那么只需要损失值越来越大就可以达到这个目标,也就是模型预测的概率中对应于真实标签的概率越小越好,这和原来的参数更新目的正好相反。因此我只需要在输入图像中加上计算得到的梯度方向,这样修改后的图像经过分类网络时的损失值就比修改前的图像经过分类网络时的损失值要大,换句话说,模型预测对的概率变小了。这就是FGSM算法的内容,一方面是基于输入图像计算梯度,另一方面更新输入图像时是加上梯度,而不是减去梯度,这和常见的分类模型更新参数正好背道而驰。
按比例和原始数据融合 $\hat J(\theta,x,y)=\alpha J(\theta,x,y) + (1-\alpha) J(\theta,x + \epsilon sign(\nabla_x J(\theta,x,y)))$
$\alpha$ 一般取0.5
==A. Coucke, M. Chlieh, T. Gisselbrecht, D. Leroy, M. Poumeyrol, and T. Lavril, “Efficient keyword spotting using dilated convolutions and gating,” in Proc. ICASSP, 2019, pp. 6351–6355==
思想
- 用了 dilated convolution 空洞卷积和 gated activations 门激活函数;
- 只检测keyword结束位置的输出概率,做loss function计算和推理,不用max pooling loss;(我命名为)【end loss】 很好用
- 没用alignment得到边界信息,而是用VAD(这个应该都无所谓),然后对keyword end位置的输出概率做计算,这个结束位置不是固定一帧,而是一个范围$\Delta t$,也就是在这个范围内的帧的输出概率去计算loss,$\Delta t$的最优值用dev set调参;这样的好处是,模型不会倾向于在命令词音频开头就触发,不然如果说的是命令词的子词就是误触发了;?这个是怎么用的,是这个范围内都是这个标签,more label ce吗?【这个思路还挺好的】【改进,随机选这个范围内的一帧去计算?增加扰动,随机性】
- 加了mask【?】,防止模型去学习精确的边界,这个是我们所不希望学习的?
- 可以流式推理【TODO】看不懂:
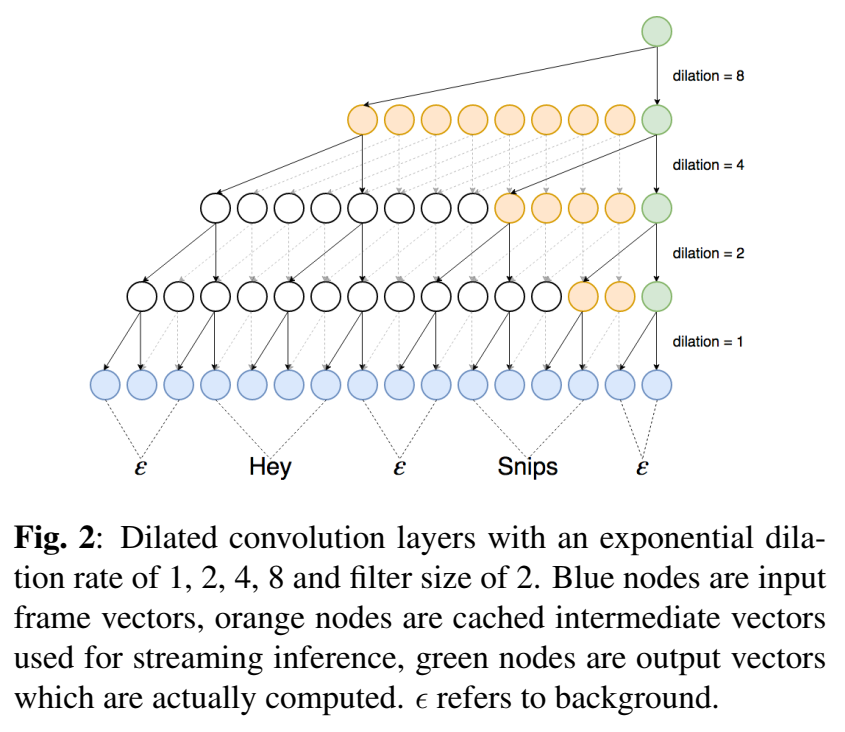
训练
- 数据集:“Hey Snips” datase (https://research.snips.ai/datasets/keyword-spotting ),a crowdsourced closetalk dataset
- 正负样本的背景音(录制场所)最好一样,防止模型训练变成分辨两种环境了
- $\Delta t$最佳值是160ms (15 frames before and 15 frames after the end of the keyword)
- 平滑窗口是30帧
- 感受野receptive field 182帧(1.83s)
- 24层,学习率1e-3,gradient norm clipping 10 ,A scaled uniform distribution for initialization
模型
参考TTS里的wavenet结构,用了Dilated causal convolutions 空洞因果卷积,门激活函数,residual连接;
Gated activations :结合了tanh和sigmoid;a combination of tanh and sigmoid activations controlling the propagation of information to the next layer ,就是cnn出来,接两个激活函数,然后相乘;
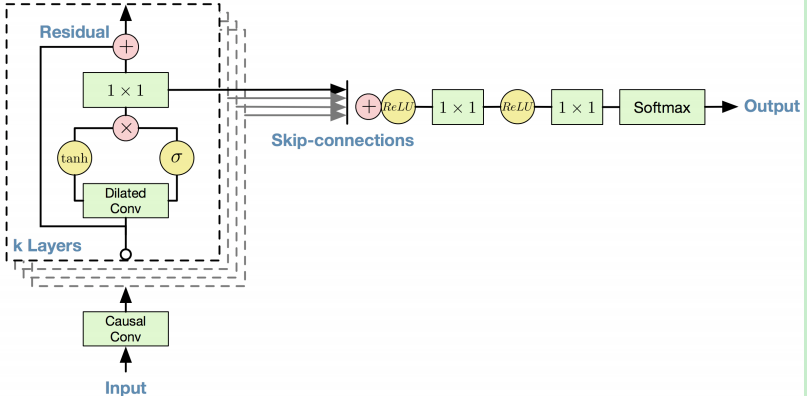
- residual connection用的矩阵是projection layer,就是正交矩阵,32维投影到16维,再恢复32维
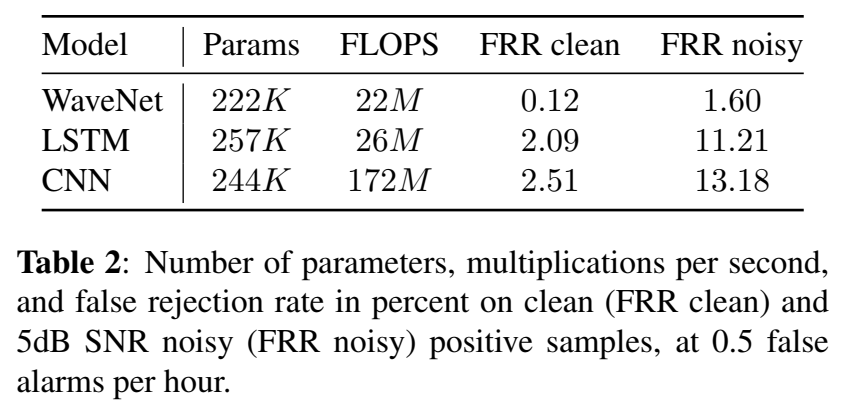
实验
- 对比模型是LSTM,max-pooling(基于ce初始模型)的模型,max-pooling loss的思想是通过反向传播损失来教会网络在其最高置信时刻触发,这种损失来自于信息量最大的关键字帧,该关键字帧具有相应关键字的最大后向。lstm输入是左拼帧10帧右拼帧10帧的stack起来作为输入(11帧的向量,比如是440维),学习率5e-5‘
- Ablation analysis 还做了消融分析
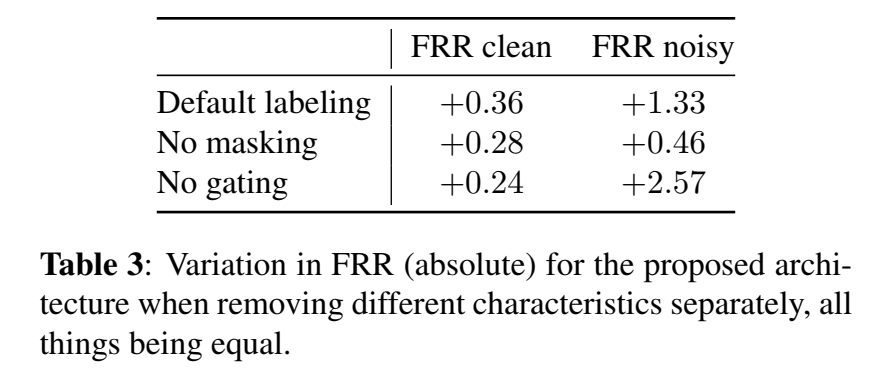
分析不同特征对识别结果的影响程度,发现end-of-keyword labeling影响最大,对FRR的改善最大,特别是在噪声环境下;
- learning rate 1e-3
结果
==Majumdar, Somshubra, and Boris Ginsburg. “Matchboxnet: 1d time-channel separable convolutional neural network architecture for speech commands recognition.” arXiv preprint arXiv:2004.08531 (2020).==ciations:28
==Mordido, Gonçalo, Matthijs Van Keirsbilck, and Alexander Keller. “Compressing 1D Time-Channel Separable Convolutions using Sparse Random Ternary Matrices.” arXiv preprint arXiv:2103.17142 (2021).==
思路
在Matchboxnet基础上,replacing 1x1-convolutions in 1D time-channel separable convolutions by constant, sparse random ternary matrices with weights in {-1; 0; +1}
==Tang, Raphael, and Jimmy Lin. “Honk: A pytorch reimplementation of convolutional neural networks for keyword spotting.” arXiv preprint arXiv:1710.06554 (2017).==
思路
- 类似wekws,也是一个框架,可以直接用!!!