命令词中文论文
==车载噪声环境下的语音命令词识别的仿真研究 涂志强 华南理工大学 2018==
- 和上一篇“基于深度学习的唤醒词识别方法研究 郭瑜 2019 大连理工大学”,思想基本一致,数据集也都相同,都用的 tensorflow 1s speech_commands 数据集
- 探索了降噪模型和识别模型结合的效果,加入降噪模型在训练识别模型可以提升1%的识别效果
==基于深度学习的语音唤醒研究及其应用 刘凯 2018 厦门大学 硕士论文==
- deep kws 置信度计算方法:


==基于深度学习的唤醒词识别方法研究 郭瑜 2019 大连理工大学==
- 基于tensorflow开发,使用python库中的提供自动语音识别功能的 Python-Speech-Features 包,用于实时录音的Py Audio 包;
- 输入一段语音,输出标签概率(many to one),概率高于阈值,则唤醒;
- 基于注意力机制的唤醒:(很奇怪c长度和帧长一致?要怎么做softmax?加权平均)
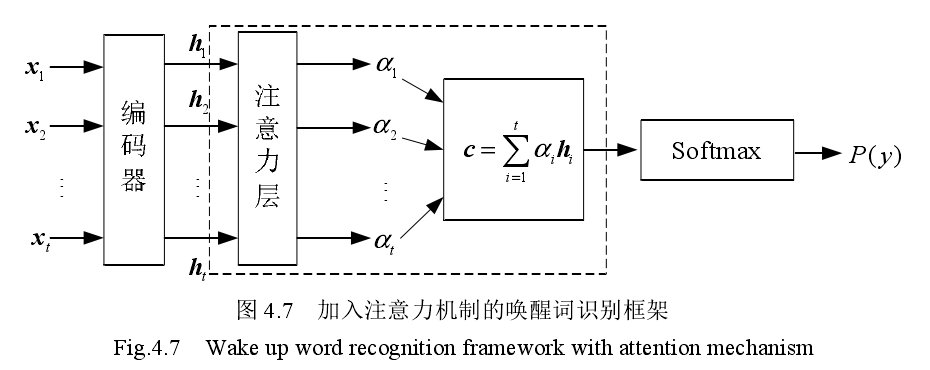
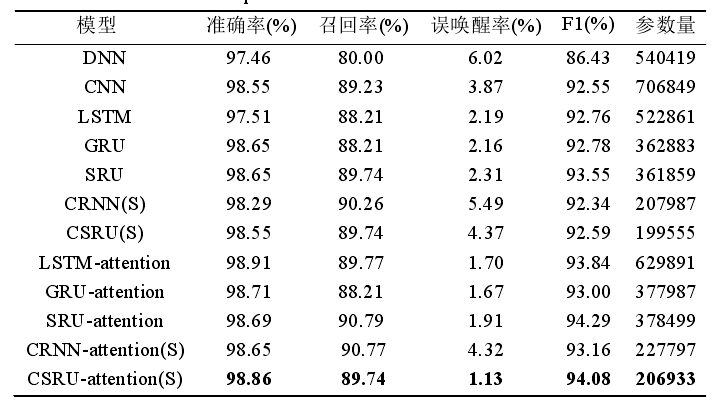
- 比较了多种神经网络:
==噪声环境下的语音关键词检测_谷悦.caj 2019 内蒙古大学==
- 语音增强和kws联合
- CRN由于bLSTM,下一步计划引入resnet
==深度学习的低延迟终端命令词识别系统设计与实现_轩晓光.caj 哈尔滨工业大学 2019==
- 得到神经网络后验概率,不是像deep kws一样做smooth,而是用将每一帧语音最大概率对应的拼音提出,构成一个拼音序列,然后去掉重复部分,再与每一个命令词的真实拼音序列求编辑距离。(这样容易不准确吧),最小距离如果小于阈值则取最小距离对应的目标词。(感觉不是很靠谱,阈值是4?)
==基于端到端的语音唤醒技术研究_张宁.2019 厦门大学 硕士论文==
- 2017年,蚂蚁金服AI部门的Zhiming Wang等人充分利用连续语音识别的语料库中庞大的语料,将DNN和CTC结合进行端到端语音唤醒,解决了关键字特定数据较少的问题[53]。Small-footprint Keyword Spotting Using Deep Neural Network and Connectionist Temporal Classifier
==基于LFMMI的两级唤醒词检测研究 陈凯斌 2020 华南理工大学 硕士论文==
- CNN-TDNNF结构
- 二级置信度评估
==面向物端芯片的语音关键词识别技术_穆维林.caj 2020 中科院计算所==
- CNN-LSTM-Attention(value似乎是一维的,c是一维向量,做sigmoid,得到输出概率)
- 量化
==语音唤醒技术在语音助手系统中的应用与实现_穆培婷.caj 2020 西安电子科技大学==
- Average attention:在这种注意力方法中,没有需要训练的参数,αt就是时间 T的平均值,$\alpha_t=\frac{1}{T}$
- CNN-GRU-Attention,固定时间长度输入(1.9s)
==基于深度学习的命令词识别方法研究_何琪琪.caj 大连理工大学 2020==
- 这篇论文还不错!可以好好看看!试试方法!
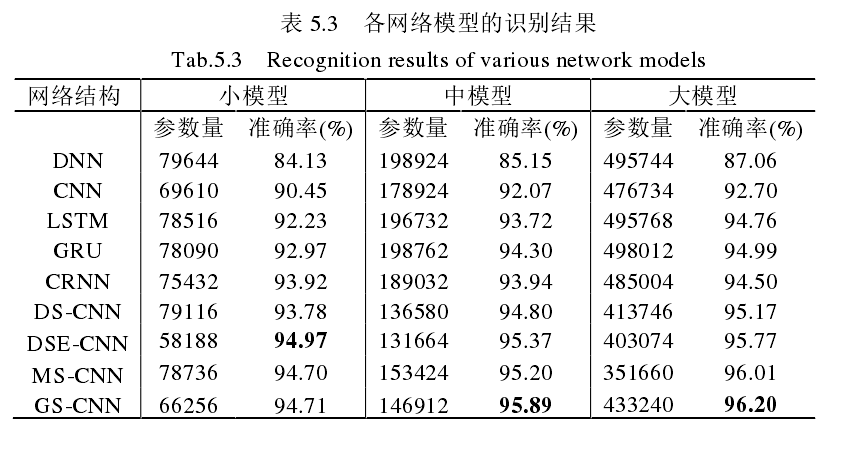
- 基于 DSE-CNN 的命令词识别方法。Depthwise-Squeeze-Excitation(DSE)模块由深度可分离卷积与 Squeeze-and-Excitation (SE) 模块结合而成。
- 使用GhostNet 中的 Ghost 模块改进 MS 模块,以去除冗余操作、减少运算量,提出Ghost-Squeeze(GS)结构。
- 帧长、帧移对结果有一点影响
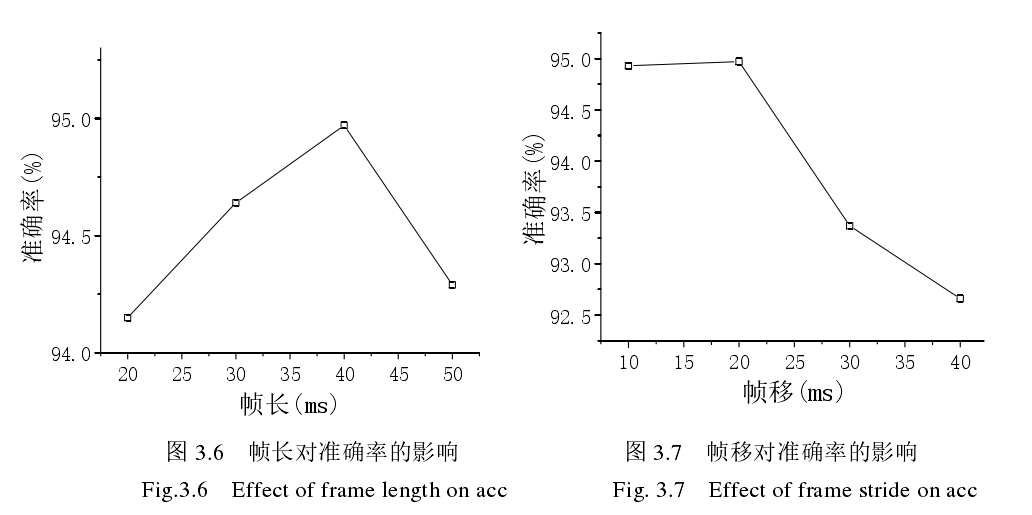
- 实验结果:
==低内存低延迟的语音关键词检测算法研究_邹台 西安电子科技大学 2020==
提出时间关注(Time Attention Convolutional Recurrent Neural Net-works,TACRNN)的语音关键词检测模型 TACRNN,也就是CRNN加入attention
CRNN结构
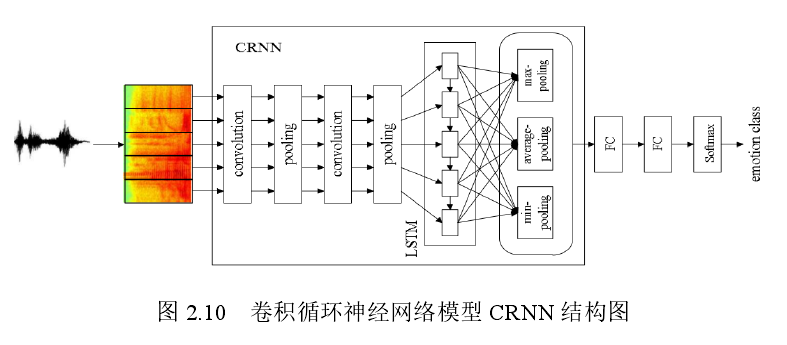
注意力机制中的 a 为对齐函数。对齐函数 a 主要有三种方式,分别为 dot、general、concat(参考了:Luong M T , Pham H , Manning C D . Effective Approaches to Attention-based Neural Machine Translation[J]. Computer ence, 2015)
- dot:$\large{a=score(h_t,\overline{h}_s)=h_t^T\overline{h}_s}$
- general: $\large{a=score(h_t,\overline{h}_s)=h_t^TW_a\overline{h}_s}$
- concat:$\large{a=score(h_t,\overline{h}_s)=v_a^Ttanh(W_a[h_t;\overline{h}_s])}$
- soft attention:就是做softmax: $\large{\alpha^t=\frac{exp(e_t)}{\sum_{j=1}^{T_x}exp(e_j)}}$
通过奇异值分解,压缩模型大小。奇异值分解可以将参数权重进行分解,之后截取重要成分,从而恢复原始的重要数据,降低数据参数。对于一个网络权重参数 W=m* n,通过奇异值分解可得,对应的三个矩阵维度分别为 m* k,k* k,k* n;奇异值处理前后的参数量即为矩阵的大小,处理前的参数 P1=m* n,处理后的参数 P2=(m* k+k* k+k*n),得到前后参数的比值为 $\large{\frac{P_1}{P_2}=\frac{mn}{(m+n+k)k}}$
取秩大小 k=2,分别对应语音关键词的时间维度和频率维度,对语音关键词检测网络进行压缩;(因为这里输入时间定长,比如100帧,频率维度固定,比如10,100* 10的输入,然后做SVD分解),(我们TDNN输入是250维,一帧一个输出)
只对时间域做卷积(其实就是TDNN)
总体结构:
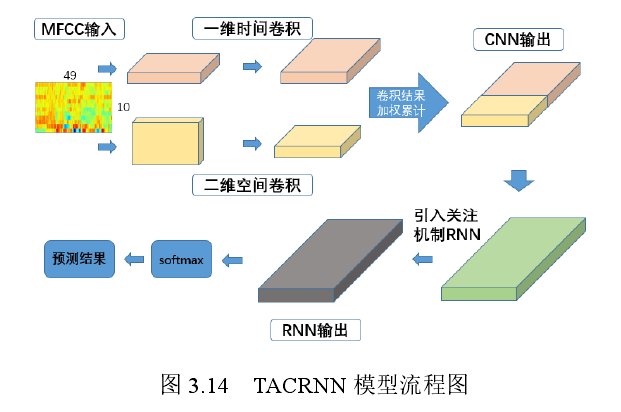
- softmax出来是一个单词的后验,但是关键词一般是不止一个单词,因此做平滑处理,常规Deep KWS平滑后验 置信度得分,分数大于阈值才换唤醒;
==冯大航–1023基于时间如何提升语音唤醒性能_v3.pptx==
- cnn-trad-fpool结构
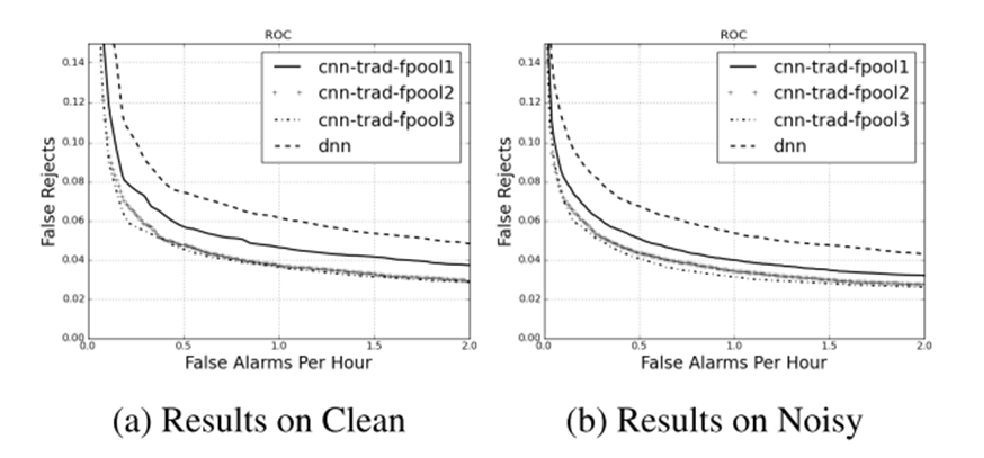
- 唤醒是一个细活,唤醒数据录音永远是有限的,而且为了在低信噪比下可以唤醒,还需要扩充一些数据。最简单的数据扩充方法,麦克风时间延迟,房间冲击响应。在单麦和多麦的仿真方法还要考虑更多的空间信息。
- 上端解码大多的方法为后验概率平滑的方法和识别两条路径的分差
- 未来趋势
- 模型压缩,小型化
- 云端的二次确认
- 前端阵列信号处理与唤醒的深度融合
- 尽可能少的唤醒词录音数据达到比较好的效果
==百度语音唤醒技术解析及实践.pdf 唐立亮==
| 方法 | 说明 |
|---|---|
| 基于置信度 | 构建唤醒识别网络,并通过某种信息等得到置信度,根据置信度是否大于指定门限来确定是否是唤醒; |
| 基于识别的唤醒系统 | 利用一套语音识别系统进行识别,往往采用语言模型作为解码的网络,根据识别结果进行后处理匹配判断是否唤醒; |
| 基于垃圾词网络 | 使用垃圾词网络进行唤醒,即选出一些垃圾词和唤醒词组成识别网络,得出最终的识别结果; |
- Wakeup Word Analysis、Garbage Phones Modification、Wakeup Dict Control、Wakeup Net Builder、Noise Suppression、Viterbi Decoder 、 DNN-HMM、FilterBank Feature Get、Voice Activity Detection、Automatic Gain Control、Confidence Decision、BigData Acoustic Model、Double Layer Decoder、Pyramid Acoustic Model、Short Word Acoustic Model
- 唤醒正确率高 :
- 唤醒词解析+动态解码
- 神经网络+大数据+CTC+短词优化
- 噪声抑制+增益控制+声学模型匹配训练
- 误报低
- 基于统计和规则的垃圾音素网络
- 置信系统
- 功耗低 省电
- 双层解码器+裁剪策略+解码器优化
- 神经网络neon运算优化
- 金字塔声学模型
==Rybakov O, Kononenko N, Subrahmanya N, et al. Streaming keyword spotting on mobile devices[J]. arXiv preprint arXiv:2005.06720, 2020.==谷歌 icassp2020