loss改进用命令词的论文
==Yandong Wen, Kaipeng Zhang, Zhifeng Li and Yu Qiao. “A Discriminative Feature Learning Approach for Deep Face Recognition” European Conference on Computer Vision (2016)..==
- 提出 center loss,目的是让相同类的特征表示尽可能相近(附带的效果:相似音是不同的类,该方法可以拉开二者距离,相当于==区分了相似音==)
- 学习每个类的deep feature的center,将输入特征的deep feature到该类中心的距离引入loss中,让类内intra-class距离小(类内方差小),目的是最小化类内距离
- 怎么让类间距离大?
- Discriminative power characterizes features in both the compact intra-class variations and separable inter-class differences,
- center loss:$\large{L_c=\frac{1}{2}\sum^m_{i=1}\Vert x_i-c_{yi}\Vert_2^2}$, (L2范数,平方距离:$\Vert x \Vert_2=(\vert x_1\vert^2+\vert x_2\vert^2+…+\vert x_n\vert^2)^{1/2}$ ,所以$\Vert x \Vert_{2}^2=(\vert x_1\vert^2+\vert x_2\vert^2+…+\vert x_n\vert^2)$ ))
- 这里的x一般是最后一层线性层之前的输入特征,比如32维,而输出一共有10个类,所以c的维度是10*32
- center $c_{yi}$ 值:在每个minibatch里,$L_c$ 对样本特征求导,累计和,乘以==学习率$\alpha$==,来更新center值(不是用平均每类的样本特征而来)(其实不用真的是特征中心点,因为目的是不同x到某点的距离最短,这个点并不重要)【改进:不同类中心的距离越大越好,也加入loss,否则不同类之间的c都很接近的话,特征还是分不开?】
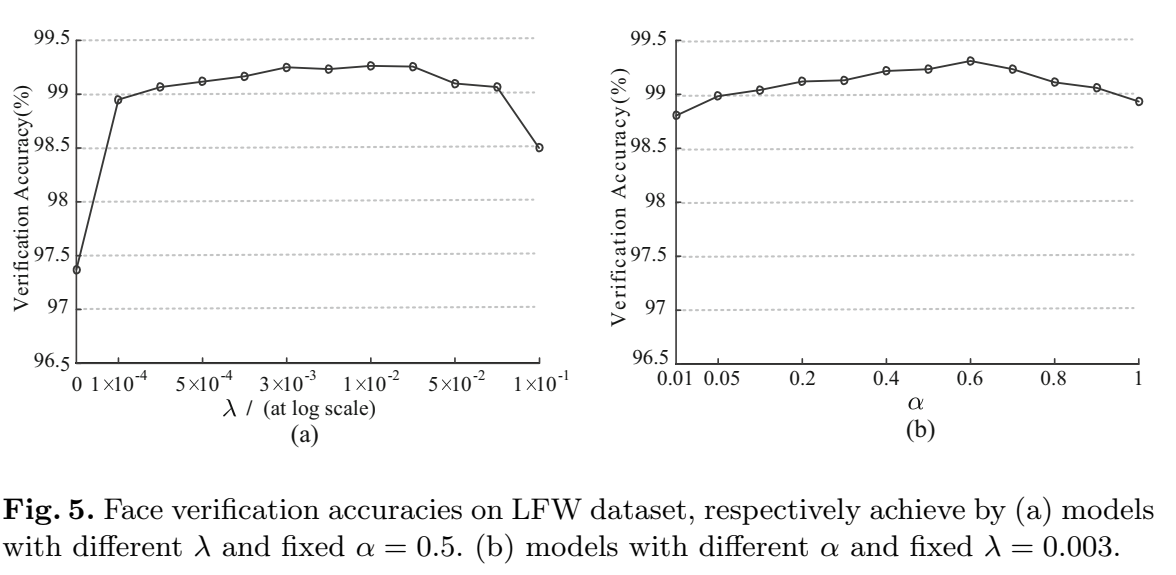
- $\lambda$:系数,用来平衡两个loss,主导了类内方差;
- $\alpha$:center loss更新center值的学习率;(决定center的参数变化量)(center loss里的参数就是指的类中心特征值)

($\theta_C$的C是卷积,不是类中心c)
- 调参:
==Hadsell, R., Chopra, S., LeCun, Y.: Dimensionality reduction by learning an invariant mapping. In: 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, vol. 2, pp. 1735–1742. IEEE (2006)==
==Sun, Y., Chen, Y., Wang, X., Tang, X.: Deep learning face representation by joint identification-verification. In: Advances in Neural Information Processing Systems, pp. 1988–1996 (2014)==
==Wen, Y., Li, Z., Qiao, Y.: Latent factor guided convolutional neural networks for age-invariant face recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4893–4901 (2016)==
- 提出 contrastive loss
- 把图像对(image pair)引入loss
- 缺点:样本一多,收敛慢 ,不稳定,可通过精细选择image pairs来缓解
==Schroff, F., Kalenichenko, D., Philbin, J.: Facenet: a unified embedding for face recognition and clustering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 815–823 (2015)==
https://omoindrot.github.io/triplet-loss#batch-hard-strategy
https://zhuanlan.zhihu.com/p/35560666
github:https://github.com/Cysu/open-reid/tree/master/reid/loss
https://bindog.github.io/blog/2019/10/23/why-triplet-loss-works/
github人脸检测:https://github.com/kuaikuaikim/DFace
- 提出 triplet loss,最小化batch内同类特征embedding $f(x)$ 距离,最大化batch内不同类特征embedding距离
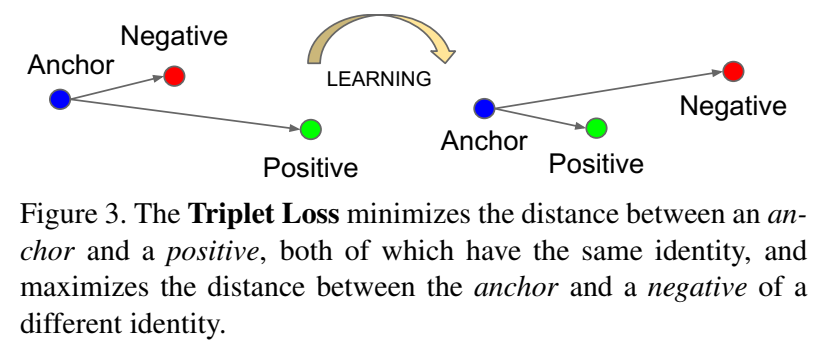
约束条件:$\large \Vert f(x_i^a)-f(x_i^p)\Vert_2^2 + \alpha < \Vert f(x_i^a)-f(x_i^n)\Vert_2^2$ ,当$\large \forall(f(x_i^a),f(x_i^p),f(x_i^n))\in T $, 其中,$T$是三元组triplet
Loss fucntion为:$\large min L=\sum\limits_i ^N \left[\Vert f(x_i^a)-f(x_i^p)\Vert_2^2 - \Vert f(x_i^a)-f(x_i^n)\Vert_2^2 + \alpha \right]$
更常用的loss是结合$max(0,d(a,p) - d(a,n) + margin)$
其中,$f(x)$ 为d维embedding特征
这个loss对于当前anchor特征,一个minibatch中p特征数量和n特征数量可能分布很不均,因此用求与p特征的argmax,与n特征的argmin,就只统计和一个同类距离和一个不同类距离作为loss,
维度d,所有维度都计算距离然后求和了(欧式距离)
但是这样会训练loss越训练,最后变成都在margin附近。。。no good
因此,不是用hardest positive,而是用所有的anchor-positive pair来算loss,anchor-negative还是用的hard negative
把图像三个一组(image triplet)引入loss,但这样收敛慢,对三元组triplet要求高
缺点:样本一多,收敛慢 ,不稳定,可通过精细选择image triplets来缓解
triplet loss里的anchor和目标检测的anchor不一样,是基于人脸识别提出的,是每个输入样本(叫做anchor)提一个embedding,和其他同类样本的embedding距离近,和不同类样本的embedding距离远作为loss(ps. 目标检测的anchor,一个图片N个anchor,理解为扫描图片,用很多框框去扫描 遍历)
Triplet Selection 来加速训练收敛:加快收敛的秘诀:找到不满足约束(难训)的triplet来训练;和同类的最远距离 与 和不同类的最近距离 如果很接近的话,说明是难训样本;两种方法来构造难训样本:
- 在每个step中offline离线产生triplet三元组,用同一个模型计算argmax同类和argmin不同类距离
- 在每个minibatch中online在线产生triplet
easy triplets、hard triplets、semi-hard triplets:
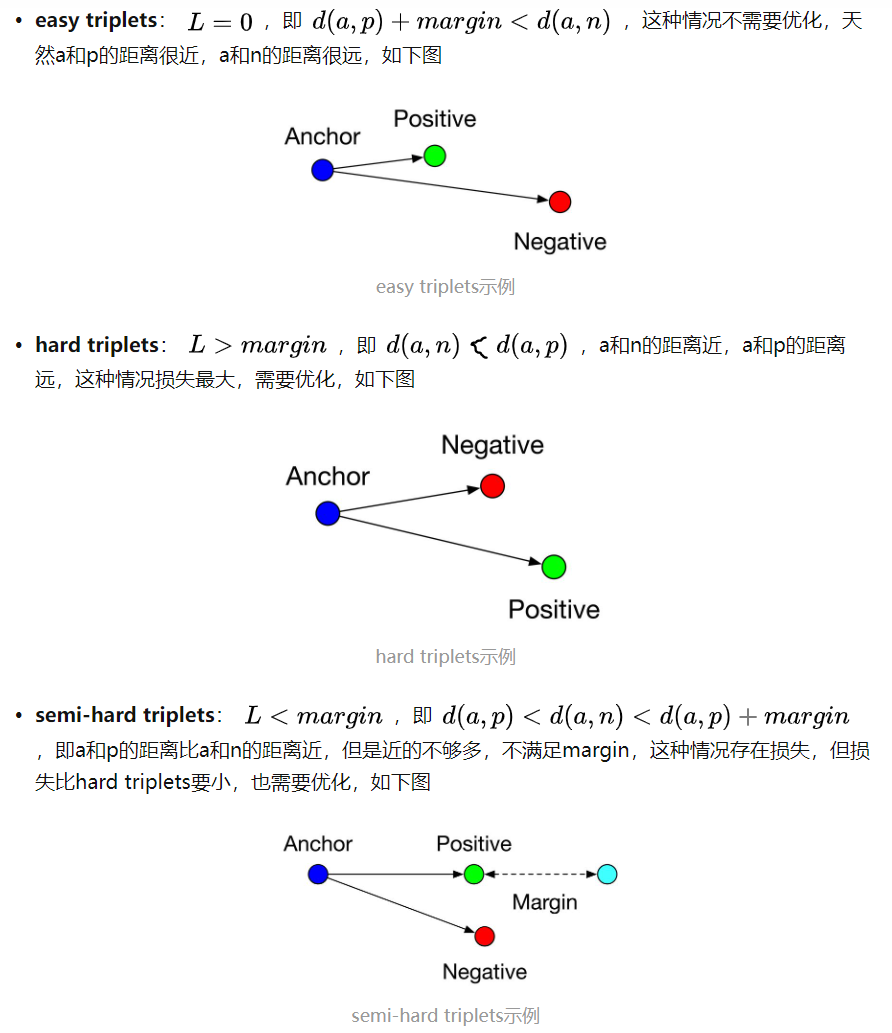
在triplet loss基础上,又衍生出了其他许多改进和变体,例如一个比较有效的方法叫hard mining,在三元组选择过程中加入一些特定的策略,尽量选择一些距离Anchor较远的Positive和距离Anchor较近的Negative(也就是最不像的同类样本、最像的不同类样本)……此类方法还有许多,就不一一列举了。
triplet loss虽然有效,但是其常为人诟病的缺点也很明显:训练过程不稳定,收敛慢,需要极大的耐心去调参……所以在很多情况下,我们不会单独使用triplet loss,而是将其与softmax loss等方法相结合使用,以稳定训练过程。
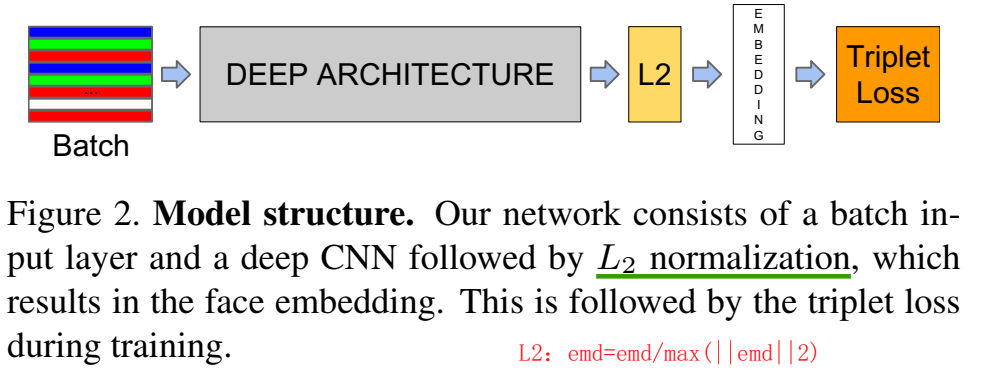
在特征embedding后接L2正则得到新的embedding特征:
特征v,有$\large v=\frac{v}{max(\Vert v\Vert_2,\epsilon)}$
hinge loss
$\large d_i \in \mathbb R^{T\times f}$
$\large d_o \in \mathbb R^{N1+N2}$
$\large I \in \mathbb R^{n\times n}$