基于隐马尔可夫模型的补白模型
Wilpon JG, Lee C, Rabiner L R, et al. Application of hidden Markov models for recognition of a limited set of words in unconstrained speech[C]. internationalconference on acoustics, speech, and signal processing, 1989: 254-257.
《用HMM在无约束的语音中识别有限集合里的词》
思想
无约束 指的是适用于一段说话语音(words embedded in speech)中 识别出关键词(之前的孤立词识别更适用于单独说出关键词,而说话语音中效果不好)
训练关键词的HMM model,输入一段语音找最优路径,看出来什么样的状态序列,根据序列里的状态确定有没有关键词。
还有个后处理过程 Postprocessor,因为最优路径还不能确定是不是关键词,还要经过后处理进一步判断。
在起止时间(i,j)内 ,算两个特征:
特征1:average model likelihood: $p(i,j)=\frac{1}{j-i+1}\sum\limits_{k=i}^j{m_p(k)}$
把最优路径的i,j起止时间内的似然分求平均
特征2:average state likelihood: $s(i,j)=\frac{1}{N}\sum\limits_{n=1}^N{s_p(n)}$
某个model有N个状态,把其中每个状态在i,j起止时间内的的平均似然求和再求平均,得到这个model的s
后处理判断准则:
- 候选词的状态持续时间要大于一个阈值
- 能量大于一个阈值
- average model likelihood 大于一个阈值
- p/s在一个范围内
训练
训练关键词hmm model过程:用word建模,用孤立词数据训练,但是这样不够,没有考虑到协同发音,因此把连续语音的关键词位置,切出来,再训练关键词的hmm model。
实验
75000句子中,有关键词的有7981句
Sun M, Snyder D, Gao Y, et al. Compressed Time Delay Neural Network for Small-Footprint Keyword Spotting.[C]. conference of the international speech communication association, 2017: 3607-3611.
《用于低功耗命令词识别的压缩的时延神经网络》
思想
用DNN-HMM,当最优路径是唤醒词时,判断唤醒词路径的似然概率,比上filler路径的似然概率,是否大于一个阈值;
要满足低功耗,对模型做了改进:
- 下采样,输入不是取一个集合比如[-2,2](共五帧),而是下采样,取离散值,比如{-2,2},只取左二帧和右二帧(共两帧)
- SVD分解(体现在bottleneck层)
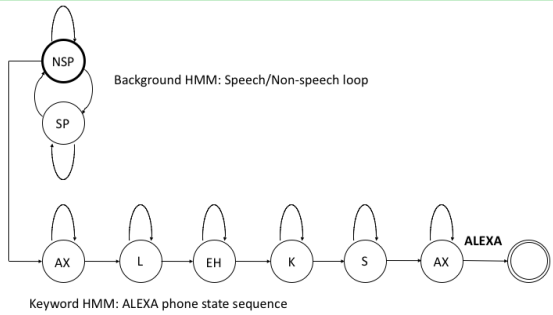
这是一个HMM model
建模单元是一个word(alexa)
这个word用多个phone组成
里面每个phone由三状态HMM的构成
不是对word去建一个模,而是通过G.fst/L.fst来限制最后的hclg路径。
O—AX:ALEXA—O—L:ϵ—O—EH:ϵ—O—
走一遍,当最优路径是唤醒词时,拿出最优路径和次优路径
最优路径,这里就是指的时维特比解码,走到某个关键词节点最优;次优路径,指的是走到非关键词的最优
下采样:
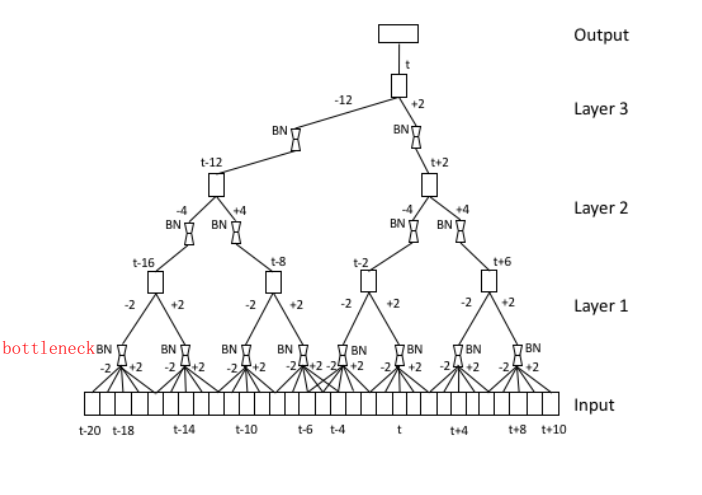
训练
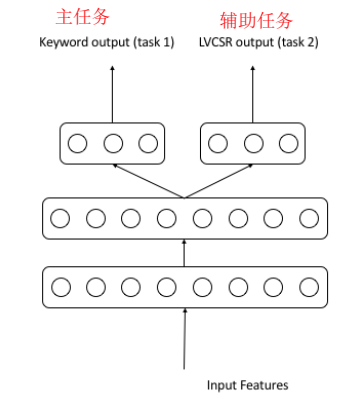
训练模型用了很多技巧
- transfer learning 迁移学习:用训练好的语音识别声学模型,作为命令词声学模型的初始模型;
- multi-task learning 多任务学习:训练命令词任务,辅助训练识别任务,最后把识别那部分移除;
- loss function:$L_t=\lambda{L_t^1}+(1-\lambda){L_t^2}$,权重因子主任务命令词=0.9,辅助任务语音识别=0.1
- SVD Approximation :为了用SVD近似训练TDNN,我们首先训练一个更大尺寸的全秩TDNN。然后,我们将全秩仿射矩阵的SVD初始化的线性瓶颈层添加到TDNN中,从输入层开始,每次一层。每加一个bottleneck层,就要训练一轮epoch
训练流程:
- 训练一个全秩LVCSR TDNN、结构和全秩命令词TDNN一样,识别模型用于TDNN初始化;
- 在步骤1的网络结构上添加一层分开的隐藏层,一部分给命令词任务,一部分给识别任务,再一层输出层;$output_1=yw_1$,$output_2=yw_2$;
- 训练步骤2的网络结果,多任务学习,loss是二者加权结合;
- 训练一些轮epoch后,添加线性bottleneck层。这些bottleneck层神经元参数的初始化来源于满秩矩阵的SVD分解;
- 每次加一个bottleneck层,就要训练一轮,然后固定了模型结构后,还要接着训练一些轮epoch;
- 移除识别任务的隐藏层,只留下命令词任务的模型结构;
实验
激活函数用sigmoid,每轮epoch学习率衰减;
训练20个epoch,SVD还要训练20个epoch;
这篇论文核心是提出一个效果好的模型,由于没有统一公开的测试集,要怎么证明模型效果好呢?通过和其他模型进行对比就可以。相对的。
TDNN SVD 对比 DNN SVD;对比 TDNN no SVD;保证三个模型参数量差不多。
Non-HMM based KWS
DNN based filler models
另一种基于神经网络分类的方法就更加直接了,如下图所示,连续语音流逐段地送入神经网络进行分类。类别为所有的关键词,和一个额外的填充类别(Filler),比如有10个关键词,就有11类。
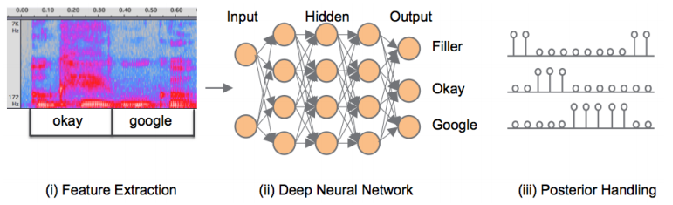
分类完成后,由于输出的概率可能出现“毛刺”,所以进行平滑后处理,之后如果某一个类别概率超过一个阈值,就认为某一个关键词被检测到了。这种方法内存占用小,不需要解码搜索,准确率高。但是由于需要准备大量包含关键词的语料,如果更换了关键词,则需要再另行搜集一批语料,所以也较难实际使用。相比之下,基于隐马尔可夫模型的Keyword Spotting由于是针对子词单元建模,语料用通用的就可以,所以更常用。
(一段语音一段语音地送入DNN,得到这一段语音,比如100帧的100个输出,每个输出有11分类的概率,平滑一下,看看关键词分类的概率是否高过阈值,判断关键词是否被检测到–yl)
- DNN is used as a framewisely classifier.
- Then the posteriors are smoothed with a window.
- The system is used in mobile devices.
Chen G, Parada C, Heigold G, et al. Small-footprint keyword spotting using deep neural networks[C]. international conference on acoustics, speech, and signal processing, 2014: 4087-4091.
思想
- Deep KWS:没有走HMM(生成出state序列,state映射为keyword phone/sutrbword,再viterbi解码找最优路径)的方法,而根据一段时间窗口内的DNN输出,根据DNN输出后验概率得到置信度分数confidence score,与阈值比较,判断是否有keyword;
- dnn输入时会拼帧,类似TDNN,输入是一个拼帧的向量(左10帧右30帧),一帧对应一个label,输出label只有 n个keyword + non-keyword;每帧都会有一个标签,(一个输入对应一个输出,所以并不是一个多帧输入对应一个输出的问题)
- loss function:$\large F(\theta)=\sum_j{logp_{i_jj}}$,j是第j帧,i是第i个label
- Posterior smoothing:平滑后的概率 $\large p(i,j)=\frac{1}{j-h_{smooth}+1}\sum\limits_{k=h_{smooth}}^j{p_{ik}}$
- $\large h_{smooth}=max{1,j-w_{smooth}+1}$
- Confidence 置信度 $\large confidence=\sqrt[n-1]{\prod\limits_{i=1}^{n-1}\max\limits_{h_{max}\le{k}\le{j}}{p’_{ik}}}$
- 把类别乘起来,看看命令词的概率有多大,但这样比如说OKOK,或者GOOGLE GOOGLE,没办法区分的
训练
本文的Deep KWS方法如果用asr数据训出的asr模型,和KWS迁移学习训练,效果会比只用命令词数据训练KWS更好。
baseline(对比模型)采用的是HMM KWS model:
- 基于HMM的不需要keyword的训练数据,用asr训好的,就能作为keyword用,通过解码限制L吧。
- 基于HMM的命令词模型的训练数据里,如果有命令词数据,效果会更好。
实验
测试时用了带噪语音测试
2.3K training examples for each keyword, and 133K negative examples, comprised of anonymized voice search queries or other short phrases.
asr模型用3000 hours;
注意
参考 书籍《Kaldi语音识别实战》P206
- 基于单音素建模对于一些唤醒词来说是比较重要的一个优化。
- 在原始论文中,神经网络的输出节点是以词为单位进行建模的,一个输出节点对应一个完整的词。对于“OK Google”这种每个词都包含几个音节的唤醒词来说是比较合适的,但是对于一些语言,如中文,就不是特别合适了。举例来说,一个汉字,如果不考虑音调的话,有可能对应非常多的其他汉字,因此在中文中以词或字为建模单元,比较容易造成误唤醒。对于==中文==这样的语言,可以采用==单音子为建模单元,效果往往会比以字或词为建模单元更优==。建模单元的选择往往取决于具体的唤醒词,对于特定的唤醒词,读者也应该尽可能多地尝试不同的建模单元。
- 雷博解释:因为“OK”、”Google”音素不重合,概率值是把平滑后”OK”的概率乘以平滑后”Google”的概率,但是中文音素容易重合,相乘的时候拿音素概率会拿到同一个。。?
- 解码处理部分也是优化空间比较大的点。在原始论文中,笔者采用对神经网络输出节点对应后验概率取最大值并做几何平均的方式来计算特定窗口中出现唤醒词的置信分数。对于“OKGoogle”这种只有两个词,并且以整词为建模单元的唤醒词来说,这样的处理方式是合理的,但是对于中文唤醒词,如果以单音素作为建模单元,则==一个唤醒词中的不同地方可能出现相同的音素==,原始论文中的解码处理方法就不太适用了。这种情况下,==我们依然可以采用滑动窗口的处理方式,但是需要利用维特比算法(ViterbiAlgorithm)求解窗口中的最佳路径,并计算最佳路径对应的置信分数==。读者也可以尝试完全抛弃滑动窗口的处理方式,采用其他更复杂的解码处理方法。
- 对于语音唤醒应用来说,误唤醒是非常重要的一个指标,过高的误唤醒会直接影响用户体验,甚至可能导致用户停止使用整个语音功能。为了压制误唤醒,可以采用二阶段唤醒的框架。二阶段唤醒又分为云端二阶段唤醒和设备端二阶段唤醒。云端二阶段唤醒的实现比较简单,一般的做法是,设备端的第一阶段唤醒引擎被唤醒了之后,设备会把保存下来的唤醒词传输到云端,云端可以利用更加复杂的模型(比如语音识别模型)对上传过来的音频做二次确认,如果云端模型也判断为唤醒词,则认为真的出现唤醒词了。不足之处是,由于需要经过网络传输,唤醒词的确认过程会有一定的延时。设备端二阶段唤醒受制于设备端上有限的计算资源。往往不能采用像谱音识别这样的复杂模型来进行二次验证。
- 通用的做法是训练一个简单的基于逻辑回归或神经网络的分类器。从第一阶段唤醒引擎中,我们可以提取诸如置信分数、延时、时长等一系列的信息,这些信息可以作为第二阶段分类器的输入特征,训练分类器做出是否唤醒词的判断。二阶段唤醒可以极大地降低出现误唤醒的概率。值得一提的是,在二阶段框架中,训练数据的选择会变得非常重要。我们建议读者尽可能多地采集生活中可能出现的音频数据,用第一阶段引擎筛选出容易造成误唤醒的片段,然后针对性地训练第二阶段分类器来对误唤醒进行压制。
- 还有其他一些技巧也有助于唤醒引擎的优化,比如数据增强、尝试不同的神经网络模型结构、神经网络模型压缩等,本节不再一一展开介绍。
Wu M, Panchapagesan S, Sun M, et al. Monophone-based background modeling for two-stage on-device wake word detection[C]//2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018: 5494-5498.
思想
- two stage,用命令词模型的DNN输出,提取67维特征,作为二级DNN的输入
- 把filler model不是简单的用non speech和非命令词speech训练,而是把每个音素也作为分类label,使得filler model数量变多,命令词模型的DNN输出提取的不止67维,更高维,作为二级DNN输入,也就是说filler model分类变多,命令词的label类别变多,效果反而会提升。
He Y, Prabhavalkar R, Rao K, et al. Streaming small-footprint keyword spotting using sequence-to-sequence models[C]//Automatic Speech Recognition and Understanding Workshop (ASRU), 2017IEEE.
==Bai Y, Yi J, Ni H, et al. End-to-end keywords spotting based on connectionist temporal classification for mandarin[C]//2016 10th International Symposium on Chinese Spoken Language Processing (ISCSLP). IEEE, 2016: 1-5.==
思想
- 用 LVCSR 做kws
- 用CTC代替DNN-HMM
- 用 timed factor transducer 进行decode
实验
用 EESEN 框架训练 ctc model
CTC建模单元mandarin syllable
CTC输入特征 MFCC 优于 FBank
ps.雷博:走fst不用限制时长(比如固定1s、2s),可以一直走很长fst,直到有命令词。