命令词专利
CN201811475797-语音唤醒方法及装置、处理器、音箱和电视机-申请公开.pdf 阿里巴巴 陈梦喆 薛少飞 雷鸣 2018
思想
- 前端信号处理和kws串联 训练(前端信号处理、kws都用的网络)
- 前端信号处理的输出信号与原始信号 一起送入kws的am
存在问题
- 前端信号处理用网络了,功耗大
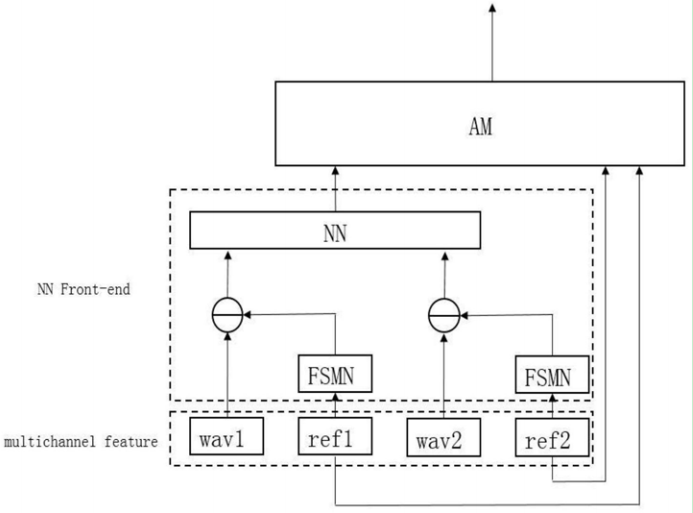
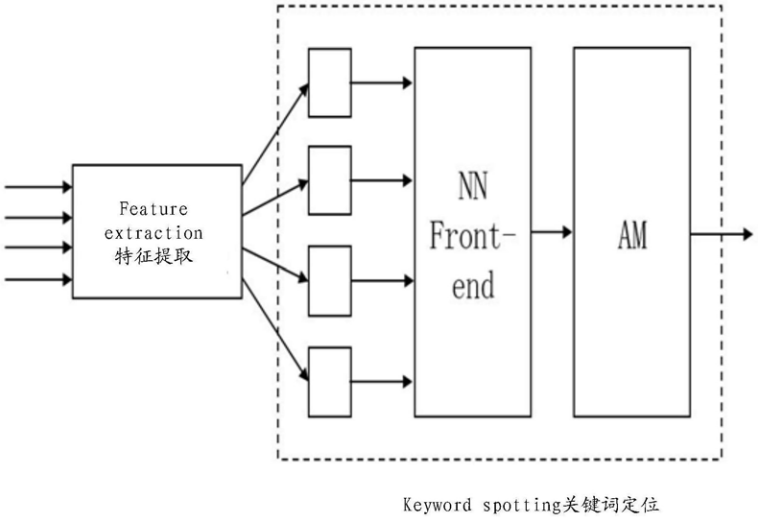
CN201910094806-唤醒模型的确定方法及装置-审定授权.pdf 声智科技 靳源 陈孝良 冯大航 苏少炜 常乐 2019
背景
- 由于唤醒模块的建立,一般是特地录制关于唤醒词的语音信息,用于训练神经网络。且在神经网络的训练过程中,更新整个神经网络每一层的各个参数。这样一般花费较多的时间,成本较高,且神经网络的训练运算量太大,容易出现误差,因此,得到的唤醒模型的精确度也不高 。
思想
- 提出一种模型参数更新的方法
- 将训练集中的任一批次训练唤醒数据输入至一基于神经网络的识别模型,确定所述神经网络的隐层的最后一层的当前状态的参数,所述参数包括权重与偏移量; (更新了一次iter),对所述识别模型的隐层的最后一层的前一个iter的状态的参数与当前状态的参数进行插值处理,确定一插值,并将所述插值更新为当前状态的参数。
- 也就是说,更新了iter的模型参数后,没有马上把这个参数用于下一个iter的训练,而是把这个参数与前一次iter的参数进行插值,得到新的参数。
CN201910095418-语音唤醒的优化装置及方法-申请公开.pdf 声智科技 冯大航 陈孝良 苏少炜 常乐 2019
思想
- 两个阈值Y1,Y2,客户端一个唤醒模型A,云端一个唤醒模型B,经过A的输出Y:
- Y<Y1:没唤醒
- Y>Y2:唤醒
- Y1<Y<Y2,送入B,得到Y’:
- Y’<Y1:没唤醒
- Y’>Y1:唤醒
CN201910815261-一种语音唤醒的识别方法、装置及电子设备-审定授权.pdf 声智科技 陈孝良 靳源 冯大航 常乐 2019
思想
- 检测到唤醒时,取出唤醒词边界,多帧后验概率,送入二分类器,判断是否唤醒
- 二分类器:基于预先训练的唤醒模型,计算每个目标数据帧属于预设的第一语音段的概率;所述预设的第一语音段为属于语音信号且不包括唤醒词的数据。总概率低于阈值:唤醒;总高率高于阈值:误唤醒
- 概率:每个目标数据帧的短时能量和过零率 ;第一个字的各个音素的后验概率相加,得到每个数据帧属于所述唤醒词的第一字的后验概率值;
CN201910872875-一种语音唤醒方法及装置-申请公开.pdf 声智科技 陈天峰 冯大航 陈孝良 常乐 2019
思想
- 唤醒后,把非唤醒词(
)的边界抽出,非唤醒词边界内的音频能量和声学特征 送入神经网络,得到一个分数,唤醒词分数和非唤醒词分数,得到一个置信度,再根据阈值判断是否唤醒
CN202010268839-一种命令词识别方法及装置-申请公开.pdf 声智科技 张猛 冯大航 陈孝良 2020
思想
- 构造命令词的解码图进行缩减大小,相同的字进行复用,比如去XX楼,去和楼的状态是复用的,去XX楼,只需在去增加arc到XX,XX增加arc到楼
CN202010537664-音频数据的存储方法、装置、终端及存储介质-申请公开.pdf OPPO 陈喆 2020
思想
- 多级模型,从而得知是哪个地方拦住了唤醒
- 第一级语音唤醒识别模型筛选后,可以去除采集到的无效音频;
- 第二级语音唤醒识别模型用于识别音频数据是否包含完整唤醒词,用于去除包含与唤醒词较接近的其他关键词的音频数据
- 得到第n级语音唤醒识别模型输出的音频特征向量,与预先设置的标准特征向量进行比较
CN202010573699-一种语音唤醒系统及方法-申请公开.pdf 长虹电器 朱海 王昆 周琳岷 2020
思想
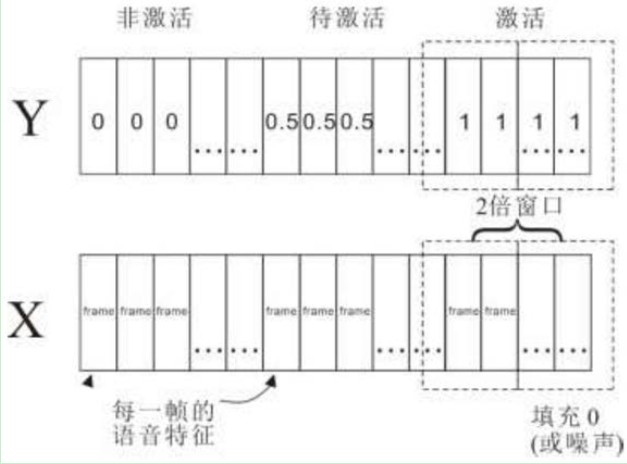
- 模型:LSTM、WaveNet、CNN、CRNN 中之一
- 有三类:激活、待激活、非激活。预测每一帧为非激活、待激活、激活标记的概率,采用滑动窗口,只在激活词的尾部进行唤醒
- 正样本末尾特殊标记方式为以尾部端点为中心,在前后各一个窗口大小的范围内标记为激活,其余范围标记为待激活,负样本则全部标记为非激活
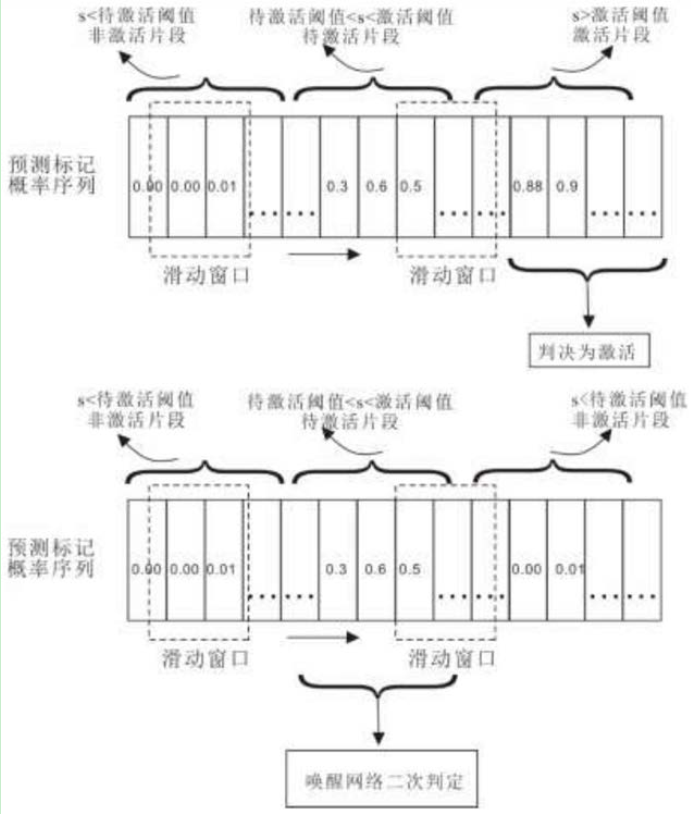
- 若滑动窗口内平均值大于激活阈值,则判决为唤醒;
- 若滑动窗口内平均值介于激活阈值与待激活阈值, 并且此后窗口小于待激活阈值,则将待激活的语音帧片段用语音唤醒网络做二次判定,再判决是否唤醒。
CN202010634922-语音唤醒方法及装置-申请公开.pdf 声智科技 杨晓帆 冯大航 陈孝良 2020
思想
- 两个模型,一个命令词模型,输出每帧后验,音素后验和,大于一个阈值,送入第二个模型;第二个模型,图片识别模型,输入边界的语谱图和后验概率图
CN202010672496-一种基于多命令词的语音唤醒方法及其系统-申请公开.pdf 芯声智能 王蒙 姜黎 胡奎 付志勇 2020
思想
- PCEN特征->神经网络->每帧概率分数->概率连续大于阈值20帧->检测到关键词
- 神经网络组成:CNN->GRU->Attention
- CNN:对应特征数量,生成大小固定的等量卷积核; 拼接卷积核内积的结果,得到CNN层的输出特征
- label:命令词/非命令词;或者:命令词1/命令词2/…/非命令词
- 每次送入20帧:获取连续20帧的预测概率值,并解码; 累计预测概率值的大小和次数,当预测概率值连续几帧都大于设定的测试阈值时判定为检测到关键词。这种方案相比与滑窗机制,在预测方面识别率会稍有下降,但是计算量缩小将近百倍
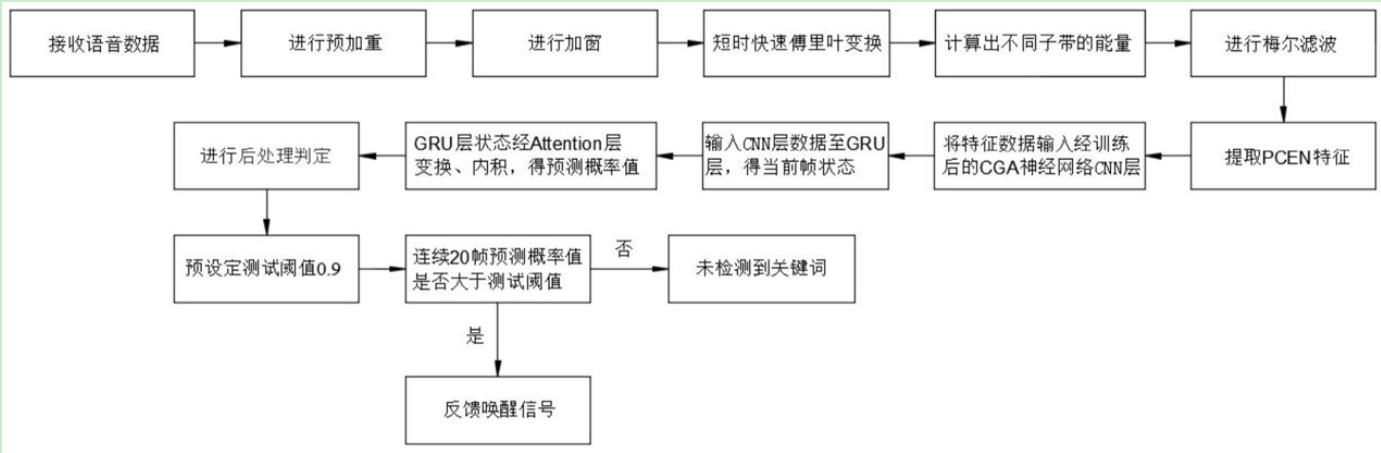
存在问题
- 20帧就能够判断是否命令词了吗?读一个小源岂不是也能唤醒,误唤醒是否会很高
CN202010795017-语音唤醒方法、装置、电子设备和存储介质-申请公开.pdf 小米 张秀云 2020
思想
- 多级唤醒处理,每一级准确度递增,前面几级准确度低,但是功耗低,也能排除一部分,判断为误唤醒就不会进入下一级
CN202010801109-一种语音处理方法及装置、存储介质-申请公开.pdf OPPO 陈喆 曹冰 胡宁宁 2020
CN202110437391-一种语音唤醒方法及装置-申请公开.pdf 中国科学院声学研究所 黎塔 刘作桢 张鹏远 颜永红 2021
- attention的RNN-T,输出每一帧的分类后验,每个音素逐帧概率求和与阈值比较,贪心解码,最小编辑距离
CN202110168131-语音唤醒方法、装置、芯片、电子设备及存储介质-申请公开.pdf 汇顶科技 何婷婷 王乐临 王鑫山 朱虎 2021
- VAD->声纹->唤醒词识别
[好]CN202011630785-语音唤醒方法和装置-申请公开.pdf 思必驰 薛少飞 2021
sinc函数构造带通滤波器
CNN不适合低功耗唤醒设备的原因:
- 计算量大,一维卷积核长度a,音频长度L,步长1,计算量至少a*L
- 对时间序列缺乏“ 记忆”:CNN由于结构的限制,对于之前的输入缺乏“ 记忆”功能,当前的输出仅和当前的输入有关。
- 对时间序列缺乏“ 记忆”主要是由于CNN网络对时间序列缺乏“ 记忆”是由它的网络结构决定的。一方面,对于卷积层来说,卷积只对卷积核覆盖到的区域进行计算,因此卷积核外的语音信息不会对当前卷积核内语音信息的处理产生影响
- 尽管由于全连接层的存在,各卷积核之间的信息仍会相互影响,但这种影响仅限于网络输入的总时长(通常为30ms)以内,无法在较长的时间尺度上进行信息传递。
FSMN缺点:无法对原始语音信号直接进行处理,直接用原始语音信号作为模型输入进行训练,效果会很差。 FSMN模型缺乏直接从原始音频数据中学习有用信息的能力,因此通常在使用FSMN模型之前需对原始音频进行特征提取。
sinc函数来构造带通滤波器,形成一种特殊的卷积层,该滤波器的参数为最高和最低截止频率,而这两个参数的值由网络学习得到
CN202011599330-语音唤醒方法、装置、计算机设备和存储介质-申请公开.pdf 杰理科技 匡勇建 2021
- 解码完,根据解码分数,提出引入一个建模单元时长相关的惩罚函数,音素常规时长区间以外的音素,乘以惩罚函数,得到新的解码分数,根据分数与阈值判断是否唤醒
- 惩罚函数,采用gamma曲线函数,$f(t)=1,t\geq{t1},and,t\leq{t2}$, $f(t)=Gramma(t),t<t1,or,t>t2$
CN202011568957-语音处理方法和电子设备-申请公开.pdf vivo 李俊潓 2021
- 减少误唤醒方法:唤醒后进行声纹识别
CN202011565487-一种唤醒方法、装置及终端-申请公开.pdf 思必驰 王文成 董芳芳 樊冰玉 吴翔 2021
- 减少误唤醒方法:唤醒后进行周围是否有人检测
- 周围是否有人检测:距离传感器得到距离,得到声音强度,查找声音强度-距离对应关系表;红外特征信息是否符合人体红外特征信息,查找声音强度‑人体红外特征强度对应关系表
CN202011547352-一种命令词识别方法及设备-申请公开.pdf 地平线 单长浩 2021
- 在声学模型上做文章,TDNN引入残差网络,第二层送入第三层与第五层,第三层送入第四层与第六层
- 引入注意力机制,多级输出?
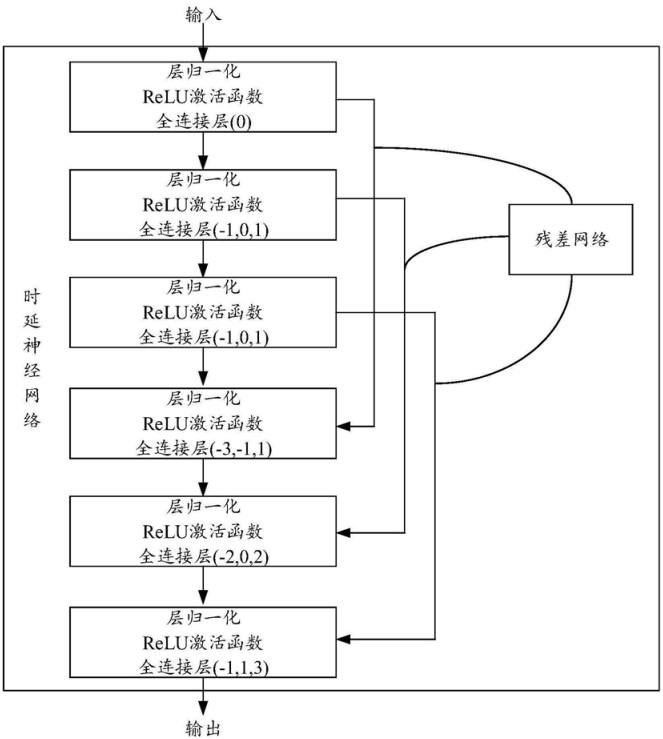
CN202011453041-语音唤醒方法及装置、可读存储介质、电子设备-申请公开.pdf 单长浩 2021
普通的注意力机制训练的模型由于对其学习到的知识过度自信,导致语音唤醒系统的性能相对较低,误唤醒率相对较高
用识别模型,提取bottlenect特征,无监督?,作为第二个模型的输入,第二个模型结构用了注意力机制,输出字,。。。。
基于多个第一语音特征的时序,通过多个第一语音特征分别对应的音素 概率分布形成音素概率分布序列,之后,确定出该音素概率分布序列中的目标音素序列,基 于该目标音素序列,确定第一唤醒概率。作为一种可能的情况,目标音素序列为唤醒词音素 序列,目标音素序列的概率为第一唤醒概率。举例来说,唤醒词是小爱同学,则唤醒词音素 序列(目标音素序列)为“ x iao3 ai4 t ong2 x ue2”,其中,数字3、4、2分别表示汉语音节 中的三声调、四声调和二声调,确定音素概率分布序列中存在唤醒词音素序列(目标音素序 列)的概率,并将该概率确定为第一唤醒概率。作为另一种可能的情况,针对每个音素概率 分布,确定音素概率分布中最大匹配概率值对应的示例音素,通过每个音素概率分布分别 对应的示例音素组成目标音素序列。作为一种可行的实现方式,计算目标音素序列与唤醒 词音素序列之间的相似度,并将该相似度确定为第一唤醒概率。作为另一种可行的实现方 式,构建词级别的声学模型,其中,词级别的声学模型确定语音波形中每个词的概率,基于 词级别的声学模型,得到目标音素序列对应的词序列,计算词序列与唤醒词序列之间的相 似度,并将该相似度确定为第一唤醒概率,这里,需要将连续多个第一语音特征进行拼接, 将拼接后的特征输入至词级声学模型中进行识别。
CN202011502794-语音唤醒方法、装置、电子设备及可读存储介质-申请公开.pdf 百度 周毅 左声勇 2021
- 避免误唤醒,常见的方法是:采集能够导致误唤醒的音频,利用该些音频对语音助手中的语音识别模型进行训练,以使得语音助手识别出误唤醒的声音后,不会进入唤醒状态。 但这样效率很低
- 核心思想:不同的环境音量对应不同的唤醒精度 ,根据环境音量的大小,调整唤醒精度。当前环境越嘈杂,语音助手越难被唤醒。比如,用户想要唤醒语音助手,就得清晰、大声的发出“ 小黑小黑”
CN202011474857-一种语音唤醒方法、装置、电子设备及存储介质-申请公开.pdf 有竹居网络(字节跳动) 田垚 姚海涛 蔡猛 2021
用RNNT网络,由于RNN‑T中预测网络prediction network 的角色类似于语音识别中语言模型的角色,通过输入上一个字(词)来预测下一个字(词),由于训练数据中存在非常多唤醒词的数据,这些数据对应的文本都是一样的,会导致预测模型出现过拟合,从而利用模型进行语音唤醒时会出现非常多的误唤醒现象,影响语音唤醒的准确性。
在种子RNN‑T模型的基础上添加前向神经FFNN网络,其中,FFNN(Feed Forward Neural Networks )网络与编码器网络连接;将种子RNN‑T模型(通用识别数据训)作为第一分支,将FFNN网络和编码器网络(识别数据+唤醒数据训)作为第二分支;根据第一分支和第二分支获得自适应唤醒模型。 loss:加权和,多任务学习。
并不是分两部分走,唤醒数据只用来finetune,先用通用识别数据训一个模型,再用识别数据+唤醒数据进行finetune(自适应) 的多任务学习方法。
在对自适应唤醒模型进行训练时,唤醒词数据不会经过预测网络,从而可以解决由于唤醒词所对应的文本都是一样的,而导致预测网络出现过拟合的情况。
测试时,得到两个分支概率,概率和和阈值关系判断是否唤醒
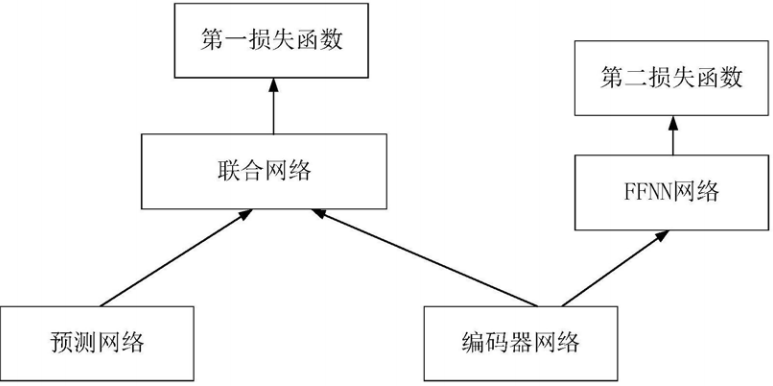
CN202011436338-命令的识别方法、装置及计算机可读存储介质-申请公开.pdf 鹏城实验室 黄炜 钟晓雄 张伟哲 束建钢 艾建文 黄兴森 2021
- google推荐的MnasNet(google搜索建立模型的方法)的最优骨干网络搭建方式,建立由输入端到输出端的网络
- 由于矩阵中大部分为负样例,正样本对Loss的贡献度非常的小,这样会导致均值平均精度(mAP,mean Average Precision)训练不充分,为此引入处理正负样本不均衡的方法,将原有的交叉熵损失改进为如下公式, $CrossEntropy(t,p)=-(e^{a(1-p)}tlog(p)+(1-t)*log(1-p))$ ,类似Focal Loss ,为了提高正样本对Loss的贡献,其中α为控制该指数的上升速度,t为对应的标签,p为模型输出的值
- 利用了声纹特征
- 判断特征向量与特征向量库是否匹配
CN202011302212-语音唤醒方法及装置-申请公开.pdf 思必驰 王蒙 薛少飞
- 在滑动窗口内对所获取的音频数据进行归一化处理,以生成相应的目标特征数据;将所述目标特征数据提供给语音唤醒模型 ,可以避免突变的声场环境因归一化操作而被削弱的影响,有助于提高终端设备在较嘈杂的声学环境中的唤醒率。 这不就是sliding cmvn?
- PCEN(Per-Channel Energy Normalization , 单通道能量归一化算法)是一种能量泛化算法,其可以对没有取对数的音频特征进行单通道能量归一化处理,能够替代特征提取部分的取对数运算,具有较强的声学自适应性。此外,通过测试结果显示,在远场测试环境下具有提升唤醒率的效果
- 在声音产生突变时,可能导致配置有PCEN算法的语音识别模型无法唤醒的情况,其一般是基于IIR(infinite impulse response , 无限脉冲响应)滤波器的,导致初始状态会一直对当前状态产生影响,而在声场环境突变时,特征的值会产生较大的改变,经过归一化处理后,这个改变被削弱,从而对唤醒结果产生一定影响。
==CN202011238207-一种语音唤醒方法、装置、介质和设备-申请公开.pdf 声智科技 冯大航 陈孝良 韩赞 常乐 2021==
- 每一级唤醒模块确定是否应唤醒智能设备的时长均不大于对应的设定值,从而可以通过负载均衡的方式,减轻每一级唤醒模块的计算量,降低每一级唤醒模块的功耗,避免计算能力不足的问题。
[好] ==CN111816165A-语音识别方法、装置及电子设备.pdf 声智科技 陈孝良 冯大航 郭震 2020==
- 提出在不同的语言模型上进行两次解码,一个是命令词的语言模型,一个是通用数据语言模型,得到识别解码序列,根据解码分数,确定解码结果是来自哪个解码网络的结果;
- 提出识别模型训练方法,用要训练模型的预测概率向量和已训练模型的预测概率向量的KL散度,放进loss函数;
==D1-CN112133294A-语音识别方法、装置和系统及存储介质-公开.PDF 标贝 王杰 李秀林 2020==
- 不是直接用transformer的beam search输出作为识别结果,而是受语言模型限制,把语言模型构建wfst,用声学分数在里面搜索,才得到识别路径